Fundamentals of AI Engineering
Foundational Models
Transformers
Fine Tuning
Vector Databases
RAG
LangChain
While Transformers initially revolutionized natural language processing (NLP), their applications have extended beyond text into computer vision (CV) and multimodal AI. Unlike traditional convolutional neural networks (CNNs), which operate on spatial hierarchies, Vision Transformers (ViTs) treat images as sequential data, processing them with self-attention mechanisms. Furthermore, multimodal AI models like CLIP, DALL·E, and Stable Diffusion enable seamless integration of multiple data types, such as text, images, and audio.
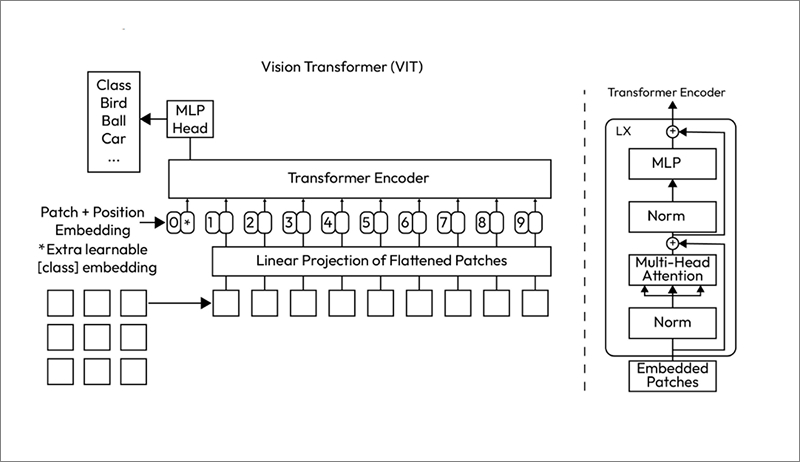
1. Vision Transformers (ViTs)
How Transformers Work for Images
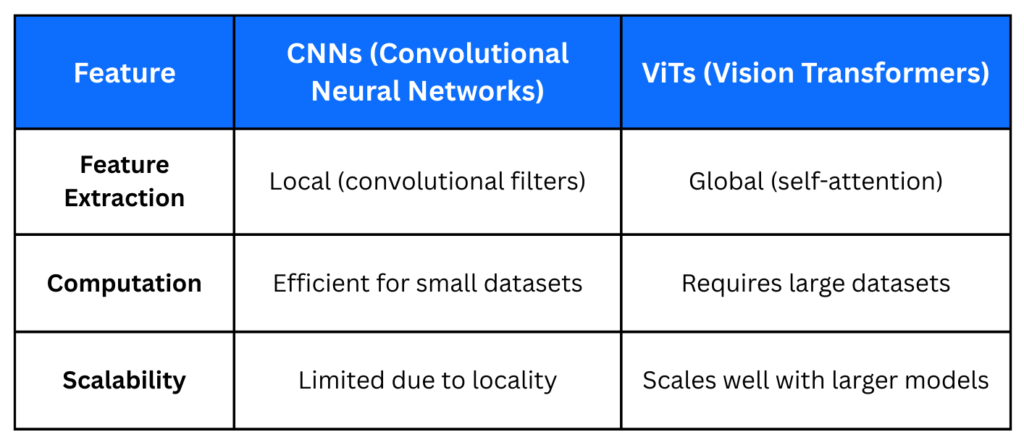
Traditional CNNs process images by extracting hierarchical spatial features through convolutional layers. In contrast, ViTs split images into patches, each treated as a sequence token, and apply self-attention to model global dependencies.
Key Steps in ViT Processing:
- Image Tokenization – The image is divided into fixed-size patches (e.g., 16×16 pixels).
- Patch Embeddings – Each patch is flattened and mapped into a high-dimensional space.
- Positional Encoding – Since Transformers lack inherent spatial structure, positional encodings are added.
- Self-Attention – The model learns relationships between patches using multi-head self-attention.
- Classification Head – A special
[CLS]token is used to aggregate image features and classify the image.
ViT vs. CNNs
Advanced Vision Transformers
Beyond ViT, several specialized models have been developed:
- DETR (Detection Transformer) – Uses cross-attention for object detection.
- Swin Transformer – Introduces hierarchical patch embeddings for better efficiency.
- ImageGPT – Autoregressively generates images pixel-by-pixel, similar to GPT in NLP.
2. Multimodal AI – Combining Text, Images, and More
What is Multimodal AI?
Multimodal AI refers to models that process and generate multiple types of data, such as text, images, and audio. Unlike single-modality AI (e.g., NLP-only or vision-only models), multimodal AI enhances understanding by leveraging cross-modal learning.
Key Multimodal Transformer Models
CLIP (Contrastive Language-Image Pretraining)
Developed by OpenAI, CLIP is trained on (image, text) pairs to learn joint embeddings of images and textual descriptions. It enables:
- Zero-shot image classification (e.g., “find an image of a dog”).
- Image-to-text retrieval and vice versa.
- Semantic search, where users can query images with natural language.
DALL·E – Text-to-Image Generation
DALL·E models use diffusion transformers to generate images from text descriptions. These models create high-quality, AI-generated artwork based on text input.
Stable Diffusion – Open-Source Image Generation
Stable Diffusion is a text-to-image model that generates high-resolution images from textual descriptions using latent diffusion models (LDMs). Unlike DALL·E, Stable Diffusion can run locally on GPUs, making it more accessible.
Transformers have transcended beyond text-based applications, powering breakthroughs in computer vision and multimodal AI. Models like Vision Transformers (ViTs), CLIP, DALL·E, and Stable Diffusion demonstrate the potential of self-attention across various domains. By leveraging large-scale training and multi-modal integration, AI systems continue to push the boundaries of creativity and automation.