Fundamentals of AI Engineering
Foundational Models
Transformers
Fine Tuning
Vector Databases
RAG
LangChain
In Transformer models, multi-head attention and positional encoding are two critical mechanisms that enable the model to process input sequences efficiently and capture complex dependencies.
- Multi-head attention enhances the ability of self-attention by allowing multiple attention mechanisms to run in parallel.
- Positional encoding provides the necessary sequence order information that is otherwise missing in Transformers.
Multi-Head Attention
What is Multi-Head Attention?
Multi-head attention is an extension of the self-attention mechanism that improves the model’s ability to capture different types of relationships between words. Instead of applying a single attention function, multiple attention heads operate in parallel, each learning distinct contextual information.
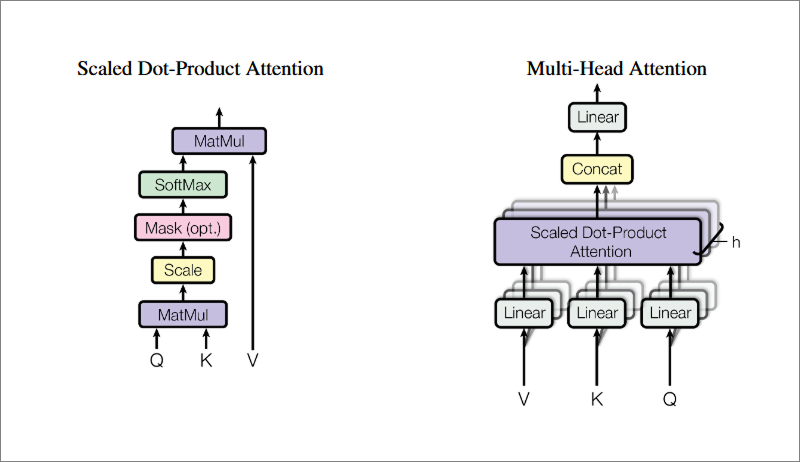
Process of Multi-Head Attention
- Linear Transformation: The input embeddings are projected into Query (Q), Key (K), and Value (V) matrices using learned weight matrices.
- Splitting into Multiple Heads: The Q, K, and V matrices are divided into multiple smaller sub-matrices, each corresponding to an individual attention head.
- Scaled Dot-Product Attention: Each head independently computes attention scores, applies softmax normalization, and generates an attention-weighted output.
- Concatenation and Projection: The outputs of all attention heads are concatenated and passed through a final linear transformation to integrate the information.
This approach allows the model to focus on multiple aspects of a sentence simultaneously, improving comprehension of complex relationships.
Mathematical Formulation
Each attention head operates independently using the scaled dot-product attention:

where:
- ( Q ) (Query), ( K ) (Key), and ( V ) (Value) are projections of input embeddings.
- ( d ) is the dimension of the key vectors.
- The softmax function ensures that attention scores sum to 1.
For multi-head attention, multiple sets of ( Q, K, V ) matrices are computed:
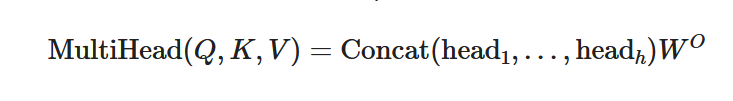
where each head is computed using the scaled dot-product attention formula.
Benefits of Multi-Head Attention
- Captures different linguistic patterns: Different heads learn different types of relationships (e.g., syntactic vs. semantic dependencies).
- Improves model expressiveness: By splitting attention across multiple perspectives, the model captures a richer representation.
- Enhances parallelization: Multiple attention heads operate independently, making the model efficient on GPUs.
Positional Encoding
Why is Positional Encoding Needed?
Unlike RNNs, which process sequences step by step, Transformers process entire sequences in parallel. This means Transformers do not inherently understand word order, which is crucial for language understanding.
To address this, positional encoding is added to the input embeddings to incorporate word order information.
How Positional Encoding Works
The original Transformer model by Vaswani et al. (2017) used sinusoidal positional encodings, where each token’s position is represented using sine and cosine functions:

where:
- ( pos ) is the position index of the token.
- ( i ) is the dimension index.
- ( d ) is the embedding dimension.
This function ensures that the positional encodings are unique for each token and allow the model to generalize to longer sequences.
Alternative Positional Encoding Techniques
Several modifications to the original positional encoding have been introduced:
- Absolute Positional Embeddings: Used in BERT and RoBERTa, where each position has a learned embedding.
- Rotary Position Embeddings (RoPE): Introduced in later models (e.g., GPT-4), encoding relative positions to capture long-range dependencies more effectively.
- No Positional Encoding (NoPE): Some researchers argue that self-attention implicitly learns position information, reducing the need for explicit encoding.
Visualization of Positional Encoding
The effect of positional encoding can be visualized using heatmaps. Models like exBERT and BertViz allow us to inspect attention maps, revealing how tokens attend to others based on their position.