Fundamentals of AI Engineering
Foundational Models
Transformers
Fine Tuning
Vector Databases
RAG
LangChain
At the core of Transformer models is the self-attention mechanism, enabling the model to evaluate the importance of each word in a sequence relative to others, regardless of their position. Unlike RNNs and LSTMs, Transformers process entire sequences in parallel, leading to greater computational efficiency and better performance in understanding contextual relationships.
Self-attention empowers models such as BERT, GPT, and T5 to excel at tasks like translation, summarization, and question answering.
Understanding Self-Attention: Key Concepts
Self-attention works by projecting each input token into three distinct vectors:
- Query (Q): Represents the current word being evaluated.
- Key (K): Represents all words in the sequence.
- Value (V): Contains the actual information for each word.
These vectors are generated by multiplying the input embeddings with learned weight matrices.
Step-by-Step Process of Self-Attention

1. Computing Attention Scores
Calculate the dot product of each Query vector with every Key vector to measure similarity:
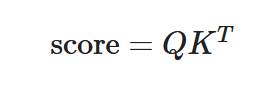
This produces a score matrix indicating the attention relevance between all token pairs.
2. Scaling the Scores
Scale the dot product scores to avoid extremely large values that can negatively impact training stability:
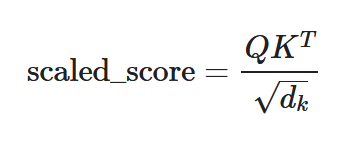
Where ( d ) is the dimensionality of the Key vectors.
3. Applying Softmax
Normalize the scaled scores into a probability distribution:
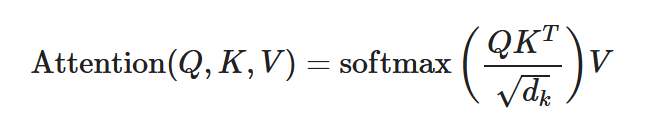
This produces attention weights that emphasize more relevant words.
4. Computing the Final Attention Output
Multiply the attention weights with the Value vectors to aggregate contextual information:
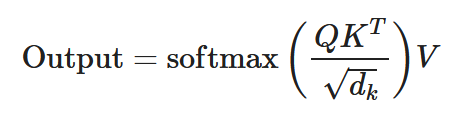
Each output vector is a weighted sum of the value vectors, emphasizing relevant words.
Multi-Head Attention
To allow the model to capture diverse types of relationships, Transformers use multiple self-attention operations in parallel:

Each head uses different projections of Q, K, and V and captures unique aspects of word dependencies.
Visualization of Self-Attention
Tools like exBERT and BertViz can visualize self-attention heatmaps, showing how each word in a sentence relates to others. For instance, in the sentence:
“Mark told Sam that he was leaving.”
A well-trained model may show strong attention from “he” to “Mark”.
Why Self-Attention Revolutionized AI
- Parallelism: Processes entire sequences simultaneously.
- Long-Range Dependencies: Captures relationships across distant tokens.
- Scalability: Suitable for large-scale training.
- Versatility: Powers tasks in NLP, vision, and beyond.
Self-attention lies at the heart of modern AI, making Transformers the foundation of state-of-the-art language and multimodal models.