Fundamentals of AI Engineering
Foundational Models
Transformers
Fine Tuning
Vector Databases
RAG
LangChain
Large Language Models (LLMs) like GPT-4, LLaMA 2, and PaLM can be accessed in two primary ways:
- API-based access → Hosted on cloud platforms (e.g., OpenAI, Google AI).
- Local deployment → Running AI models on on-premise servers or personal devices.
Each method has advantages and trade-offs, depending on cost, performance, security, and scalability needs.
1. Understanding API-Based Access
A. What is API-Based Access?
API-based access allows developers to use LLMs hosted by cloud providers without managing infrastructure.
How it works:
Send a request (e.g., user question) → API processes the request using an LLM → Returns the response.
No need to train, optimize, or host the model.
import os
from dotenv import load_dotenv
from openai import OpenAI
# Load environment variables from .env file
load_dotenv()
# Initialize the client with API key from environment variable
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
# Create a chat completion
response = client.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": "Explain Newton's Laws"}]
)
# Print the response
print(response.choices[0].message.content)B. Benefits of API-Based Access
Ease of Use → No setup required—just an API key.
Scalability → Handles large workloads without extra infrastructure.
Always Up-to-Date → Cloud providers continuously improve models.
Example:
Customer support chatbots use OpenAI APIs for automated responses, scaling seamlessly with demand.
C. Limitations of API-Based Access
Recurring Costs → Pay-per-use pricing can become expensive for heavy usage.
Privacy Concerns → Sensitive data is processed by third-party providers.
Limited Customization → Cannot fine-tune models directly.
Example:
A healthcare company may avoid API-based AI due to data privacy regulations (HIPAA, GDPR).
2. Understanding Local Deployment
A. What is Local Deployment?
Local deployment involves running an LLM on your own hardware instead of accessing a cloud-based API.
How it works:
- Download a pretrained model (e.g., LLaMA 2, Falcon).
- Run it on a server, high-end PC, or edge device.
- Fine-tune if needed for custom applications.
Example:
A legal firm deploys LLaMA 2 locally to analyze contracts while keeping data private.
B. Benefits of Local Deployment
Full Control & Customization → Fine-tune models for specific needs.
Lower Long-Term Costs → No pay-per-use API fees.
Data Privacy → All computations remain on-premise.
Example:
Financial institutions use self-hosted AI for risk analysis without exposing client data to third parties.
C. Limitations of Local Deployment
High Hardware Requirements → Needs powerful GPUs and storage.
Complex Setup → Requires installation, optimization, and maintenance.
Slower Scaling → Must manually upgrade hardware for increased demand.
Example:
A startup may struggle to run GPT models locally due to high GPU costs.
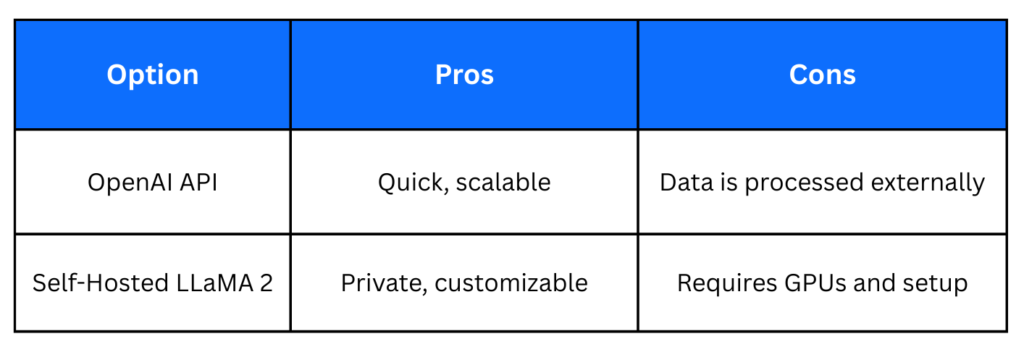
3. Key Differences Between API-Based and Local LLM Deployment

Summary:
- Choose APIs for quick deployment and scalability.
- Choose local deployment for privacy, security, and customization.
4. Choosing the Right Deployment Approach
A. When to Use API-Based Access
Best for:
Startups, small teams, and developers who need fast AI integration.
Use cases requiring real-time scaling (e.g., customer chatbots, content generation).
Example:
E-commerce platforms use API-based LLMs to generate product descriptions instantly.
B. When to Use Local Deployment
Best for:
Enterprises handling sensitive data (finance, healthcare, legal).
AI engineers needing custom fine-tuning of models.
Example:
Hospitals deploy medical AI locally to ensure patient data remains private.
5. Case Study: AI Deployment for a Law Firm
Scenario: A law firm wants an AI-powered document assistant to summarize contracts.
Final Decision:
They choose local deployment due to confidentiality concerns.
Lesson:
Businesses must balance cost, security, and flexibility when choosing AI deployment methods.